

- 8 minutos
- jun 19, 2026

A rápida evolução da inteligência artificial generativa, impulsionada pelos Modelos de Linguagem de Grande Porte (LLMs), transformou a maneira como organizações processam e consultam vastos repositórios de dados. No entanto, a natureza estática do treinamento desses modelos impõe desafios significativos, especialmente no que tange à atualização de conhecimentos e à ocorrência de alucinações em domínios técnicos ou privados. Nesse cenário, a arquitetura de Geração Aumentada de Recuperação (RAG) consolidou-se como a solução predominante para ancorar as respostas dos modelos em fontes externas de verdade.
Embora o RAG tradicional, baseado em busca vetorizada, tenha resolvido problemas de acesso a dados não estruturados em larga escala, sua incapacidade de compreender relacionamentos complexos e interdependências estruturais entre documentos revelou uma lacuna crítica. A transição para o GraphRAG e a subsequente integração de Redes Neurais em Grafos (GNNs) representam o próximo estágio na busca por sistemas de inteligência que não apenas recuperam, mas efetivamente raciocinam sobre o conhecimento.
O RAG de busca vetorizada fundamenta-se na representação matemática da semântica textual. O processo técnico inicia-se com a fragmentação de um corpus documental em unidades menores, denominadas chunks. Estes fragmentos são processados por modelos de codificação (encoders) que os transformam em vetores densos de alta dimensionalidade em um espaço latente. A premissa central é que textos com significados semanticamente próximos ocuparão regiões vizinhas neste espaço vetorial, permitindo a recuperação baseada em medidas de similaridade, como a similaridade de cosseno ou a distância euclidiana.
Esta abordagem oferece benefícios operacionais claros. Sua implementação é relativamente simples e altamente escalável, permitindo que sistemas processem milhões de documentos com latência mínima. Além disso, a busca vetorial é agnóstica à estrutura, lidando bem com textos desorganizados, transcrições e documentos semi estruturados sem a necessidade de esquemas de dados rígidos.Entretanto, as limitações deste modelo tornam-se evidentes em tarefas que exigem síntese de informações dispersas. O RAG vetorial trata cada fragmento como uma entidade isolada. Quando um usuário faz uma pergunta que requer a conexão de fatos presentes em documentos distintos — o chamado raciocínio multi-hop — a busca vetorial frequentemente falha em recuperar o contexto completo, pois não possui um mecanismo para navegar através das relações entre as entidades mencionadas.
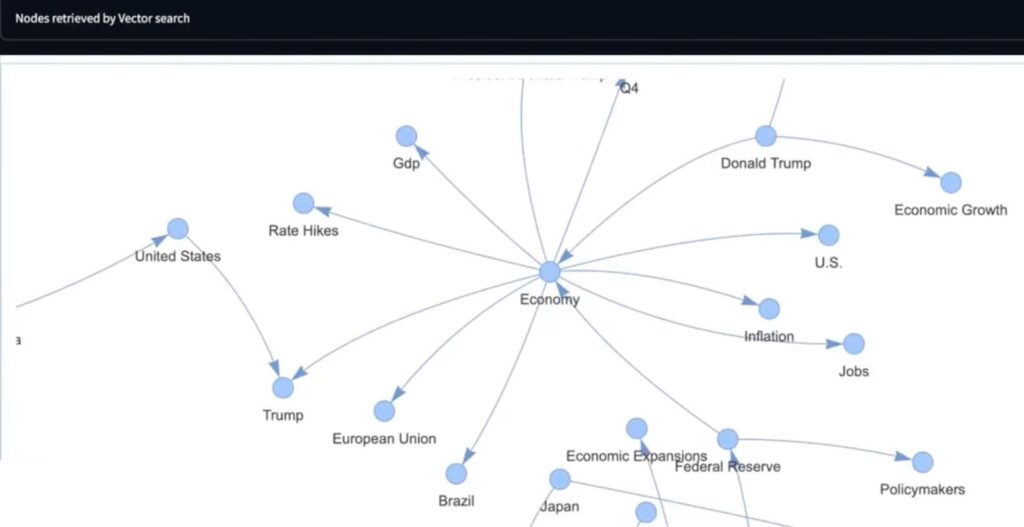
O GraphRAG surge como uma arquitetura superior ao integrar Grafos de Conhecimento (KGs) no fluxo de recuperação. Em vez de depender exclusivamente da proximidade vetorial, esta abordagem modela os dados como uma rede de entidades (nós) conectadas por relacionamentos tipados (arestas). Esta mudança de paradigma permite que o sistema capture a topologia do conhecimento, preservando o contexto estrutural que é frequentemente perdido na fragmentação linear do RAG tradicional.
No GraphRAG, a construção do índice envolve a extração de entidades e relacionamentos, muitas vezes utilizando LLMs para identificar conexões semânticas explícitas e implícitas no texto. Durante a fase de consulta, o sistema não apenas busca fragmentos similares, mas realiza uma travessia no grafo para identificar a vizinhança relevante das entidades mencionadas na pergunta.
Conforme destacado no documento Radar Tech, o GraphRAG resolve problemas fundamentais de integração e governança. Ele permite a unificação de dados estruturados, semiestruturados e não estruturados em um único grafo, facilitando auditorias e garantindo a rastreabilidade das conclusões do sistema. Além disso, a capacidade de visualizar os caminhos de relacionamento percorridos durante a recuperação confere uma explicabilidade sem precedentes ao processo de decisão da IA.
A seguir, apresenta-se uma comparação estruturada das capacidades técnicas de ambas as abordagens.
| Atributo | RAG de busca vetorizada | GraphRAG |
|---|---|---|
| Representação de dados | Vetores densos em espaço latente | Nós, arestas e propriedades (Grafo) |
| Lógica de recuperação | Similaridade semântica (Cosseno/Euclidiana) | Travessia de grafos e centralidade |
| Raciocínio multi-hop | Muito limitado; falha em conexões distantes | Nativo; conecta dados dispersos |
| Explicabilidade | Baixa; “caixa-preta” vetorial | Alta; caminhos de decisão auditáveis |
| Custo de implementação | Baixo; ferramentas prontas e rápidas | Alto; exige extração e modelagem de grafo |
| Escalabilidade de dados | Alta para volumes massivos de texto | Desafiadora para grafos altamente densos |
| Precisão em domínios técnicos | Variável; risco de alucinação por falta de contexto | Alta; baseada em fatos estruturados |
A pesquisa acadêmica e industrial divergiu em várias implementações especializadas de GraphRAG, cada uma otimizada para diferentes equilíbrios entre custo, latência e profundidade de raciocínio.
A implementação da Microsoft foca na sumarização global. Ao organizar o grafo de conhecimento em comunidades hierárquicas, o sistema consegue gerar respostas que sintetizam grandes volumes de dados em níveis variados de abstração. Embora eficaz para perguntas abrangentes sobre o corpus, essa abordagem pode ser computacionalmente dispendiosa devido à necessidade de reconstrução frequente do grafo.
O LightRAG aborda a questão da latência e do custo operacional. Diferente de sistemas que exigem reconstruções completas, o LightRAG utiliza uma estratégia de indexação incremental, onde novos documentos são adicionados unindo-se ao grafo existente sem a necessidade de reprocessar todo o repositório. Ele emprega uma recuperação de dois níveis: local (para detalhes finos) e global (para temas amplos), resultando em uma redução de até 90% nas chamadas de API e uma latência 30% menor que o RAG padrão.
Baseado na teoria de indexação do hipocampo humano, o HippoRAG orquestra LLMs e grafos através do algoritmo Personalized PageRank (PPR). Ele simula a ativação associativa da memória humana, permitindo que o sistema recupere passagens que não compartilham palavras-chave com a consulta, mas que estão ligadas por cadeias de relacionamentos semânticos. Em benchmarks como o 2WikiMultiHopQA, o HippoRAG demonstrou melhorias de até 20% sobre métodos tradicionais.
O framework KAG, desenvolvido para domínios profissionais como saúde e governança eletrônica, foca na mitigação de lacunas lógicas e temporais. Ele utiliza indexação mútua entre texto e grafo, permitindo que o sistema lide com valores numéricos, regras de especialistas e relações temporais com uma precisão significativamente superior ao RAG vetorial.
| Framework | Foco principal | Algoritmo de destaque | Vantagem competitiva |
|---|---|---|---|
| Microsoft GraphRAG | Sumarização global | Community Detection | Visão holística do corpus |
| LightRAG | Eficiência e baixo custo | Dual-Level Retrieval | Atualização incremental e baixa latência |
| HippoRAG | Memória de longo prazo | Personalized PageRank | Recuperação associativa profunda |
| KAG | Domínios profissionais | Logical-Form Reasoning | Raciocínio lógico e conformidade |
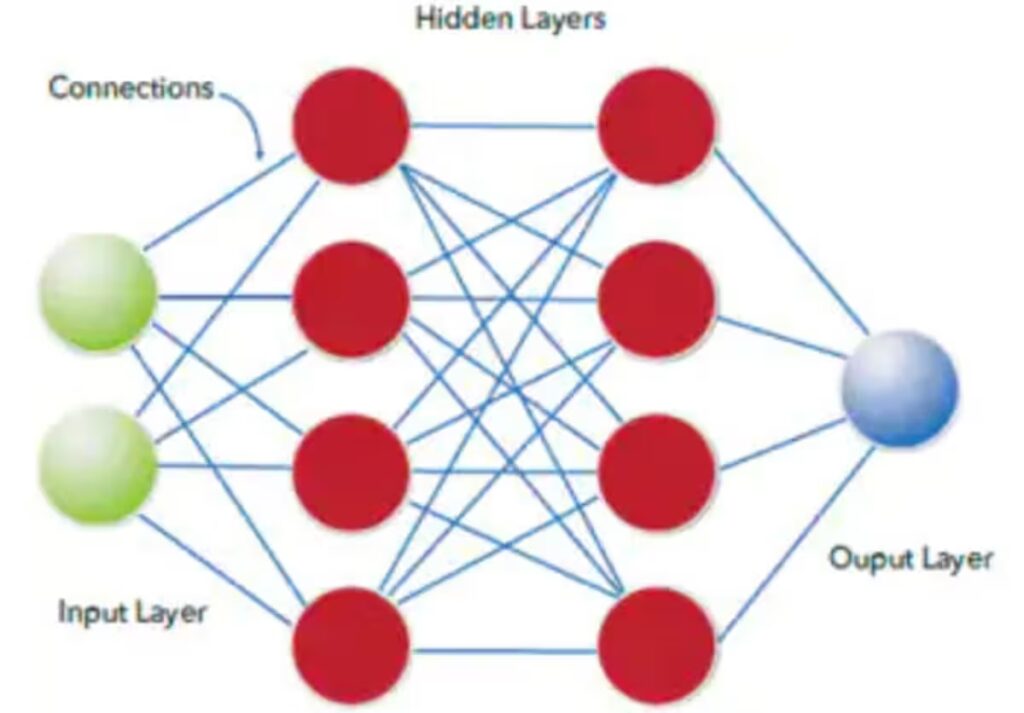
Para compreender a tecnologia que sustenta essas estruturas de grafos, é necessário revisitar os fundamentos das Redes Neurais Artificiais (ANNs). Uma ANN é uma técnica computacional inspirada no modelo biológico de neurônios de organismos inteligentes, capaz de adquirir conhecimento através de processos de aprendizado supervisionados ou não supervisionados.
Os componentes estruturais básicos de uma rede neural incluem o neurônio artificial, que recebe entradas ponderadas, soma-as e aplica uma função de ativação para determinar a saída. Estas unidades são organizadas em camadas:
O mecanismo de treinamento baseia-se na retropropagação (backpropagation), onde o erro entre a previsão da rede e o resultado desejado é calculado através de uma função de perda. Este erro é então propagado de volta pela rede, ajustando os pesos das conexões para minimizar falhas futuras.
Apesar do sucesso em dados euclidianos — estruturas regulares como grades de pixels (imagens) ou sequências unidimensionais (texto e áudio) — as ANNs tradicionais, como Redes Neurais Convolucionais (CNNs), apresentam dificuldades ao lidar com dados estruturados de forma irregular ou não euclidiana, onde as relações entre os pontos de dados são tão importantes quanto os próprios pontos.
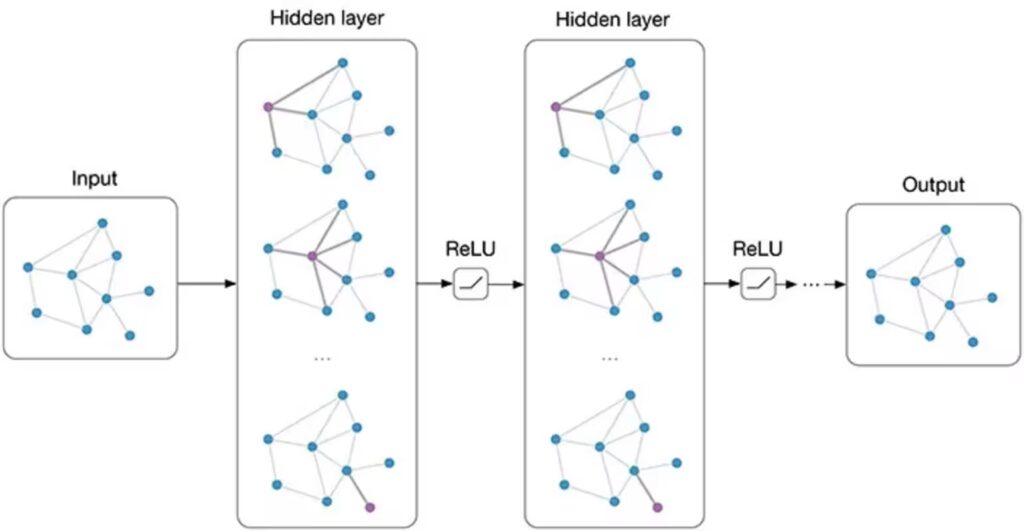
As Redes Neurais em Grafos (GNNs) representam a extensão do aprendizado profundo para domínios não euclidianos. Elas são projetadas para processar dados que podem ser representados naturalmente como grafos, onde entidades são nós e suas interações são arestas. A inovação das GNNs reside na sua capacidade de incorporar a topologia da rede no processo de aprendizado de características.
O funcionamento central das GNNs baseia-se na propagação iterativa de informações. Em cada camada da rede, um nó agrega informações de seus vizinhos imediatos para atualizar sua própria representação vetorial (embedding). Ao empilhar múltiplas camadas, a rede permite que a informação “viaje” por vários saltos, possibilitando que cada nó capture o contexto de sua vizinhança estendida.
As GNNs executam três tipos principais de tarefas:
A evolução das GNNs resultou em algoritmos que otimizam a forma como as informações são agregadas e pesadas.
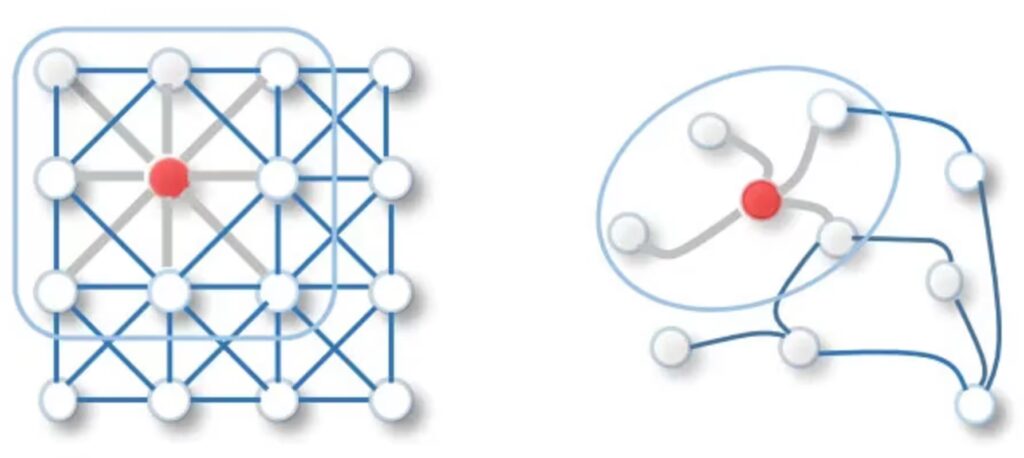
A GCN aplica uma aproximação de convoluções espectrais para operar diretamente no grafo. Ela utiliza a matriz de adjacência normalizada para ponderar a agregação de características dos vizinhos, garantindo que nós com muitos vizinhos não distorçam a escala da representação. Embora poderosa, a GCN tradicional é transdutiva, o que significa que o grafo completo deve estar disponível durante o treinamento.
A formulação matemática simplificada para a atualização de uma camada GCN é:
H^{(l+1)} = \sigma(\tilde{D}^{-1/2} \tilde{A} \tilde{D}^{-1/2} H^{(l)} W^{(l)})
$\tilde{A}$ representa a matriz de adjacência com auto-loops, $\tilde{D}$ é a matriz de grau, $H$ as representações de nós e $W$ os pesos aprendíveis.
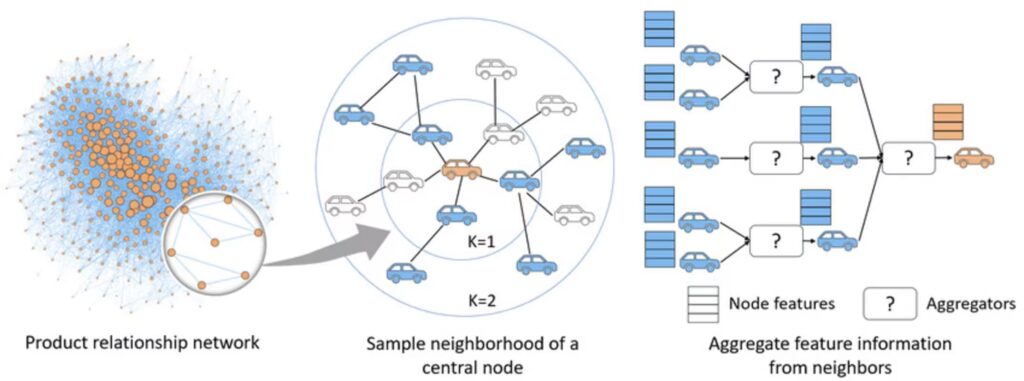
Para resolver os problemas de escalabilidade e a natureza transdutiva das GCNs, o GraphSAGE introduz o aprendizado indutivo. Em vez de aprender embeddings fixos, ele aprende funções de agregação (como média, LSTM ou pooling) que podem ser aplicadas a nós novos, não vistos durante o treinamento. Ele utiliza amostragem de vizinhança para controlar a complexidade computacional em grafos massivos.
As GATs incorporam mecanismos de atenção, permitindo que o modelo atribua pesos diferentes a vizinhos diferentes. Esta abordagem é crucial quando algumas conexões são mais informativas que outras para uma determinada tarefa. A utilização de múltiplas cabeças de atenção (multi-head attention) estabiliza o processo de aprendizado e permite capturar diferentes tipos de relacionamentos simultaneamente.
As GNNs deixaram de ser puramente teóricas para sustentar aplicações críticas em diversos setores industriais, conforme mapeado em referências como o documento Radar Tech e estudos de caso de mercado.
Na indústria farmacêutica, representar moléculas como grafos é o padrão atual. GNNs são usadas para prever a afinidade de ligação entre proteínas e ligantes, acelerando drasticamente o processo de triagem virtual de novos medicamentos. Um caso notável envolve a predição de efeitos colaterais de polifarmácia — situações onde pacientes tomam múltiplos medicamentos. Modelos de GCN conseguem prever interações medicamentosas específicas que não são detectáveis por métodos estatísticos tradicionais, modelando a rede de interações proteína-droga.
Defensores utilizam GNNs para mapear a infraestrutura de atores de ameaças. No caso do grupo FIN7 (Squeamish Libra), modelos de GNN foram treinados para identificar domínios maliciosos analisando padrões de co-hospedagem, certificados HTTPS e similaridade lexical. Enquanto pivôs manuais levavam semanas para identificar novos ativos do atacante, a automação via GNN permitiu a detecção em apenas 24 horas após o registro do domínio. Em operações de TI (AIOps), as GNNs realizam a análise de causa raiz e predição de falhas em redes definidas por software (SDN), identificando gargalos antes que impactem os usuários finais.
Empresas como a Hitachi utilizam GNNs para construir resiliência contra interrupções globais. Ao mapear a rede de fornecedores multi-tier como um grafo, as GNNs permitem identificar dependências ocultas em fornecedores críticos de “gargalo” que poderiam paralisar a produção. Benchmarks reais mostram que a aplicação de GNN na previsão de demanda e otimização de rotas resulta em melhorias de 10% a 30% na precisão operacional em comparação com modelos lineares.
Empresas como a Amazon utilizam GNNs (como o algoritmo GENI) para estimar a importância de nós em grafos de conhecimento de bilhões de objetos. Isso permite filtrar fatos triviais e focar em conexões críticas para fornecer recomendações personalizadas que consideram o contexto do usuário e as relações complexas entre produtos.
A jornada técnica descrita revela uma convergência inevitável. A busca vetorial, embora fundamental como porta de entrada para a recuperação semântica, é insuficiente para as demandas de raciocínio profundo e conformidade exigidas pelo mercado moderno. A ascensão do GraphRAG e o uso de GNNs preenchem essa lacuna, transformando repositórios estáticos de informação em redes vivas de conhecimento acionável.
O documento Radar Tech enfatiza que a importância dessa transição reside não apenas na precisão técnica, mas na governança e explicabilidade. Ao adotar sistemas que compreendem relacionamentos, as organizações podem garantir a rastreabilidade e a conformidade regulatória de suas soluções de IA. À medida que avançamos para modelos mais complexos, como o AgenticRAG, a capacidade de navegar em grafos de conhecimento estruturados será o diferencial entre sistemas que apenas geram texto e sistemas que verdadeiramente resolvem problemas complexos de domínio.
A integração final entre RAG, grafos de conhecimento e redes neurais em grafos estabelece a base para uma inteligência artificial que imita de forma mais fiel a memória associativa humana, permitindo uma integração contínua de novas experiências e conhecimentos sem os custos proibitivos do retreinamento completo de modelos de linguagem.
1. A BREAKDOWN OF GRAPH RAG VS. VECTOR RAG. In: COUCHBASE BLOG. [S.l.], [20–?]. Disponível em: <https://www.couchbase.com/blog/graph-rag-vs-vector-rag/>. Acesso em: 6 abril 2026.
2. RAG VS. GRAPHRAG: A Systematic Evaluation and Key Insights. [S.l.]: Arxiv, [2025]. Disponível em: <https://arxiv.org/html/2502.11371v3>. Acesso em: 6 abril 2026.
3. UNDERSTANDING GRAPHRAG VS. LIGHTRAG: A Comparative Analysis for Enhanced Knowledge Retrieval. In: MAARGA SYSTEMS. [S.l.], 12 maio 2025. Disponível em: <https://www.maargasystems.com/2025/05/12/understanding-graphrag-vs-lightrag-a-comparative-analysis-for-enhanced-knowledge-retrieval/>. Acesso em: 6 abril 2026.
4. GNN (GRAPH NEURAL NET) EXPLAINED— INTUITION, CONCEPTS, APPLICATIONS. In: MEDIUM: Data Science Collective. [S.l.], [20–?]. Disponível em: <https://medium.com/data-science-collective/gnn-graph-neural-net-explained-intuition-concepts-applications-7825eea73362>. Acesso em: 6 abril 2026.
5. HIPPORAG: Neurobiologically InspiredLong-Term Memory for Large Language Models. 2024. Disponível em: <https://proceedings.neurips.cc/paper_files/paper/2024/file/6ddc001d07ca4f319af96a3024f6dbd1-Paper-Conference.pdf>. Acesso em: 26 maio 2026.
6. REDES NEURAIS ARTIFICIAIS. In: ICMC/USP. [S.l.], [20–?]. Disponível em: <https://sites.icmc.usp.br/andre/research/neural/>. Acesso em: 6 abril 2026.
7. UMA INTRODUÇÃO ÀS REDES NEURAIS PARA GRAFOS (GNN). In: MEDIUM. [S.l.], [20–?]. Disponível em: <https://medium.com/@otaviocx/uma-introdu%C3%A7%C3%A3o-%C3%A0s-redes-neurais-para-grafos-gnn-60e53fcd77d6>. Acesso em: 6 abril 2026.
8. APPLICATIONS OF GRAPH NEURAL NETWORKS (GNNS). In: FRONTIERS IN. [S.l.], [20–?]. Disponível em: <https://www.frontiersin.org/research-topics/59657/applications-of-graph-neural-networks-gnns>. Acesso em: 6 abril 2026.
9. USING GNN TO IDENTIFY SUPPLY CHAIN NETWORK STRUCTURE. [S.l.]: Scholar Press, [20–?]. Disponível em: <https://scholar-press.com/uploads/papers/gwo9GeOSc2X5DJcbqL7ZvIExbm54DXEJM9kk6jIp.pdf>. Acesso em: 6 abril 2026.
10. FROM LOCAL TO GLOBAL: A Graph RAG Approach to Query-Focused Summarization. [S.l.]: Arxiv, 2024. Disponível em: <https://arxiv.org/abs/2404.16130>. Acesso em: 6 abril 2026.
11. GRAPH RETRIEVAL-AUGMENTED GENERATION: A Survey. [S.l.]: Arxiv, 2024. Disponível em: <https://arxiv.org/abs/2408.08921>. Acesso em: 6 abril 2026.
12. G-RETRIEVER: Retrieval-Augmented Generation for Textual Graphs. [S.l.]: Arxiv, 2024. Disponível em: <https://arxiv.org/abs/2402.07630>. Acesso em: 6 abril 2026.
13. GNN-RAG: Graph Neural Retrieval for Efficient LLM Reasoning on Knowledge Graphs. [S.l.]: Arxiv, 2024. Disponível em: <https://arxiv.org/abs/2405.20139>. Acesso em: 6 abril 2026.
14. HIPPORAG: Neurobiologically Inspired Long-Term Memory for Large Language Models. [S.l.]: Arxiv, 2024. Disponível em: <https://arxiv.org/abs/2405.14831>. Acesso em: 6 abril 2026.
 Newsletter
Newsletter Com a newsletter da SantoDigital, você estará sempre um passo à frente, pronto para elevar seu negócio com o poder da inovação digital.
 Estratégias vencedoras
Estratégias vencedoras  Insights do universo da tecnologia
Insights do universo da tecnologia  Soluções transformadoras
Soluções transformadoras